Team nghiên cứu của Microsoft đã tiết lộ VALL-E 2, một hệ thống AI mới để tổng hợp giọng nói có khả năng tạo ra giọng nói “hiệu suất ở cấp độ con người” chỉ với vài giây âm thanh không thể phân biệt được với nguồn.
“VALL-E 2 là tiến bộ mới nhất trong mô hình ngôn ngữ codec thần kinh đánh dấu một cột mốc quan trọng trong quá trình tổng hợp chuyển văn bản thành giọng nói (TTS) không cần mẫu đào tạo, lần đầu tiên đạt được sự ngang bằng với con người”, bài nghiên cứu cho biết.
Hệ thống được xây dựng dựa trên phiên bản tiền nhiệm VALL-E giới thiệu vào đầu năm 2023. Các mô hình ngôn ngữ codec thần kinh biểu diễn giọng nói dưới dạng các chuỗi code.
Team cho biết điều khiến VALL-E 2 khác biệt so với các kỹ thuật nhân bản giọng nói khác là phương pháp “Lấy mẫu nhận biết lặp lại” và chuyển đổi thích ứng giữa các kỹ thuật lấy mẫu. Các chiến lược này cải thiện tính nhất quán và giải quyết vấn đề phổ biến nhất theo cách nói sáng tạo truyền thống.
Các nhà nghiên cứu viết:
“VALL-E 2 tổng hợp giọng nói chất lượng cao một cách nhất quán, ngay cả đối với những câu khó hiểu do độ phức tạp hoặc cụm từ lặp đi lặp lại”, đồng thời chỉ ra rằng công nghệ này có thể giúp tạo ra giọng nói cho những người mất khả năng nói.
Tuy nhiên, công cụ này quá ấn tượng đến mức sẽ không thể cung cấp cho công chúng.
“Hiện tại, chúng tôi không có kế hoạch kết hợp VALL-E 2 vào sản phẩm hoặc mở rộng khả năng tiếp cận công chúng”, Microsoft cho biết trong tuyên bố đầy đạo đức của mình, đồng thời lưu ý rằng các công cụ như vậy mang lại rủi ro như bắt chước giọng nói mà không có sự đồng ý và sử dụng giọng nói AI thuyết phục trong lừa đảo và các hoạt động tội phạm khác.
Team nghiên cứu nhấn mạnh cần có một phương pháp tiêu chuẩn để đánh dấu kỹ thuật số các thế hệ AI, nhận thấy rằng việc phát hiện nội dung do AI tạo ra với độ chính xác cao vẫn là một thách thức.
“Nếu mô hình được khái quát hóa cho những người không nhìn thấy trong thế giới thực, thì nó phải bao gồm một giao thức để đảm bảo người nói chấp thuận việc sử dụng giọng nói của họ và một mô hình phát hiện giọng nói tổng hợp”.
Điều đó nói lên rằng, kết quả của VALL-E 2 rất chính xác so với các công cụ khác. Trong một loạt thử nghiệm do team nghiên cứu thực hiện, VALL-E 2 vượt trội hơn các tiêu chuẩn của con người về độ mạnh mẽ, tự nhiên và độ giống nhau của giọng nói được tạo ra.
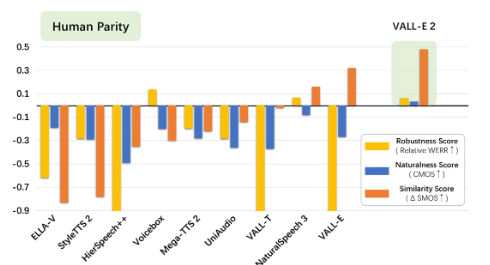
Nguồn: Microsoft
VALL-E-2 có thể đạt được những kết quả này chỉ với 3 giây âm thanh. Tuy nhiên, team nghiên cứu lưu ý rằng “sử dụng mẫu giọng nói dài 10 giây thậm chí còn mang lại chất lượng tốt hơn”.
Microsoft không phải là công ty AI duy nhất trình diễn các mô hình AI tiên tiến mà không tung ra thị trường. Voicebox của Meta và Voice Engine của OpenAI là hai công cụ sao chép giọng nói ấn tượng nhưng cũng gặp phải những hạn chế tương tự.
Người phát ngôn của Meta AI nói vào năm ngoái:
“Có nhiều trường hợp sử dụng thú vị đối với các mô hình giọng nói tổng quát, nhưng vì nguy cơ sử dụng sai mục đích, chúng tôi không cung cấp công khai mô hình hoặc code Voicebox vào thời điểm này”.
Ngoài ra, OpenAI giải thích rằng trước tiên họ đang cố gắng giải quyết vấn đề bảo mật trước khi tung ra mô hình giọng nói tổng hợp.
OpenAI giải thích trong một bài đăng trên blog chính thức:
“Theo cách tiếp cận của chúng tôi đối với an toàn AI và các cam kết tự nguyện của chúng tôi, chúng tôi đang chọn xem trước nhưng không phát hành rộng rãi công nghệ trên vào thời điểm này”.
Lời kêu gọi hướng dẫn đạo đức đang lan rộng khắp cộng đồng AI, đặc biệt là khi các cơ quan quản lý bắt đầu nêu lên mối lo ngại về tác động của AI tạo sinh trong cuộc sống hàng ngày của chúng ta.
Tham gia Telegram của Tạp Chí Bitcoin: https://t.me/tapchibitcoinvn
Theo dõi Twitter (X): https://twitter.com/tapchibtc_io
Theo dõi Tiktok: https://www.tiktok.com/@tapchibitcoin
- ZKsync ra mắt Elastic Chain để hỗ trợ mở rộng hệ sinh thái layer 2
- TikTok chuẩn bị ra mắt chatbot AI “Genie”
- ChatGPT có thể đưa người dùng đến các trang web độc hại
Đình Đình
Theo Decrypt