Bitcoin
Bitcoin  Ethereum
Ethereum  XRP
XRP  Tether
Tether  Solana
Solana  BNB
BNB  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped stETH
Wrapped stETH  Hyperliquid
Hyperliquid  Wrapped Bitcoin
Wrapped Bitcoin  Ethena USDe
Ethena USDe  Sui
Sui  Figure Heloc
Figure Heloc 








Các nhà nghiên cứu AI Trung Quốc đã đạt được điều mà nhiều người nghĩ là còn cách xa hàng thiên niên kỷ: một mô hình AI mã nguồn mở miễn phí có thể so kè hoặc vượt qua hiệu suất của các hệ thống lý luận tiên tiến nhất của OpenAI. Điều khiến điều này càng ấn tượng hơn là cách họ thực hiện: cho phép AI tự học qua thử và sai, giống như cách con người học hỏi.
“DeepSeek-R1-Zero, một mô hình được huấn luyện qua học củng cố quy mô lớn (RL) mà không có bước tinh chỉnh giám sát (SFT) ban đầu, cho thấy khả năng lý luận đáng kinh ngạc,” bài báo nghiên cứu viết.
“Học củng cố” là một phương pháp trong đó mô hình được thưởng khi đưa ra quyết định đúng và bị phạt khi đưa ra quyết định sai, mà không biết cái nào là đúng hay sai. Sau một loạt các quyết định, mô hình học cách đi theo con đường đã được củng cố bởi các kết quả đó.
Ban đầu, trong giai đoạn tinh chỉnh giám sát, một nhóm người hướng dẫn mô hình kết quả mong muốn mà họ muốn, cung cấp cho nó ngữ cảnh để biết cái gì là tốt và cái gì không. Điều này dẫn đến giai đoạn tiếp theo, Học củng cố, trong đó mô hình đưa ra các kết quả khác nhau và con người xếp hạng những kết quả tốt nhất. Quá trình này được lặp đi lặp lại cho đến khi mô hình biết cách cung cấp kết quả thỏa đáng một cách nhất quán.
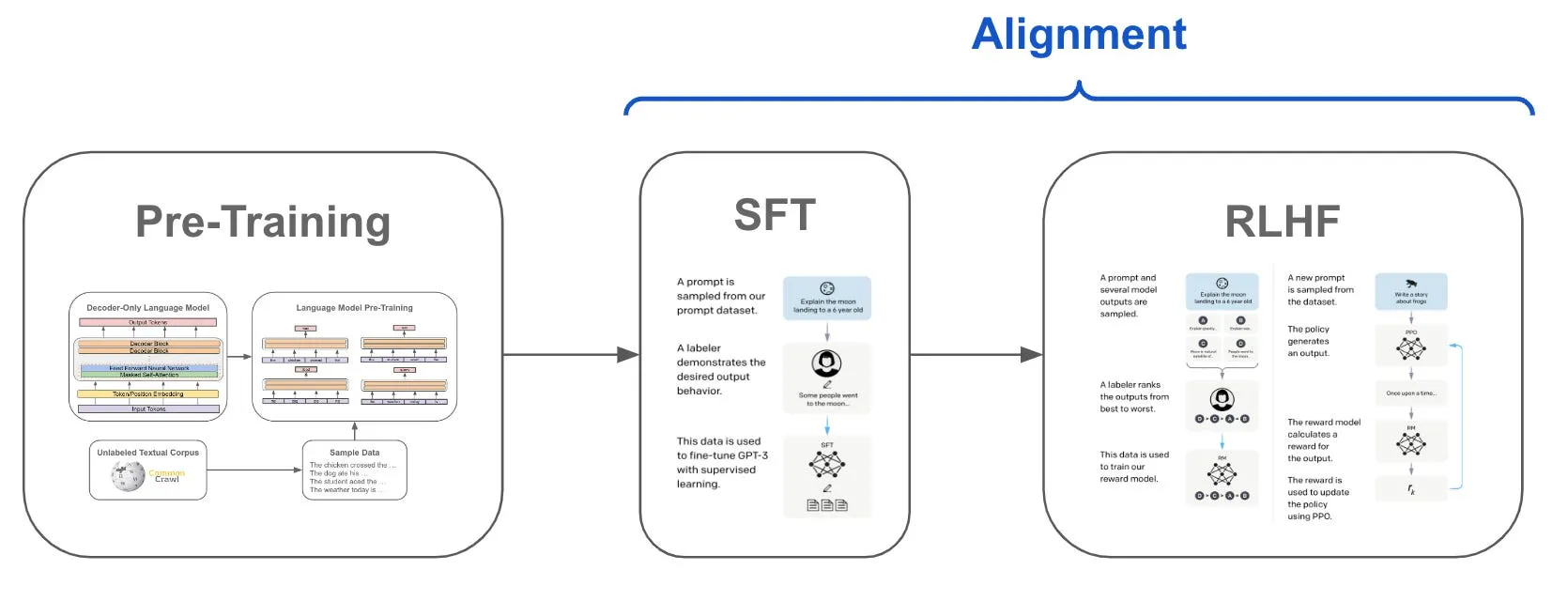
DeepSeek R1 là một bước tiến trong phát triển AI vì con người có một vai trò tối thiểu trong quá trình huấn luyện. Khác với các mô hình khác được huấn luyện trên lượng dữ liệu giám sát lớn, DeepSeek R1 chủ yếu học qua học củng cố cơ học—thực chất là tự tìm hiểu mọi thứ qua thử nghiệm và nhận phản hồi về những gì hiệu quả.
“Thông qua RL, DeepSeek-R1-Zero tự nhiên phát triển nhiều hành vi lý luận mạnh mẽ và thú vị,” các nhà nghiên cứu cho biết. Mô hình này thậm chí phát triển các khả năng tinh vi như tự xác minh và phản ánh mà không cần được lập trình cụ thể để làm vậy.
Khi mô hình đi qua quá trình huấn luyện, nó tự nhiên học cách phân bổ thêm “thời gian suy nghĩ” cho các vấn đề phức tạp và phát triển khả năng nhận ra sai lầm của chính nó. Các nhà nghiên cứu đã nhấn mạnh một “khoảnh khắc a-ha” khi mô hình học cách đánh giá lại những phương pháp tiếp cận ban đầu đối với các vấn đề—một điều mà nó không được lập trình để làm.
Các chỉ số hiệu suất rất ấn tượng. Trên thước đo toán học AIME 2024, DeepSeek R1 đạt tỷ lệ thành công 79,8%, vượt qua mô hình lý luận o1 của OpenAI. Trên các bài kiểm tra lập trình chuẩn hóa, mô hình này thể hiện “mức độ chuyên gia”, đạt xếp hạng Elo 2.029 trên Codeforces và vượt qua 96,3% đối thủ con người.
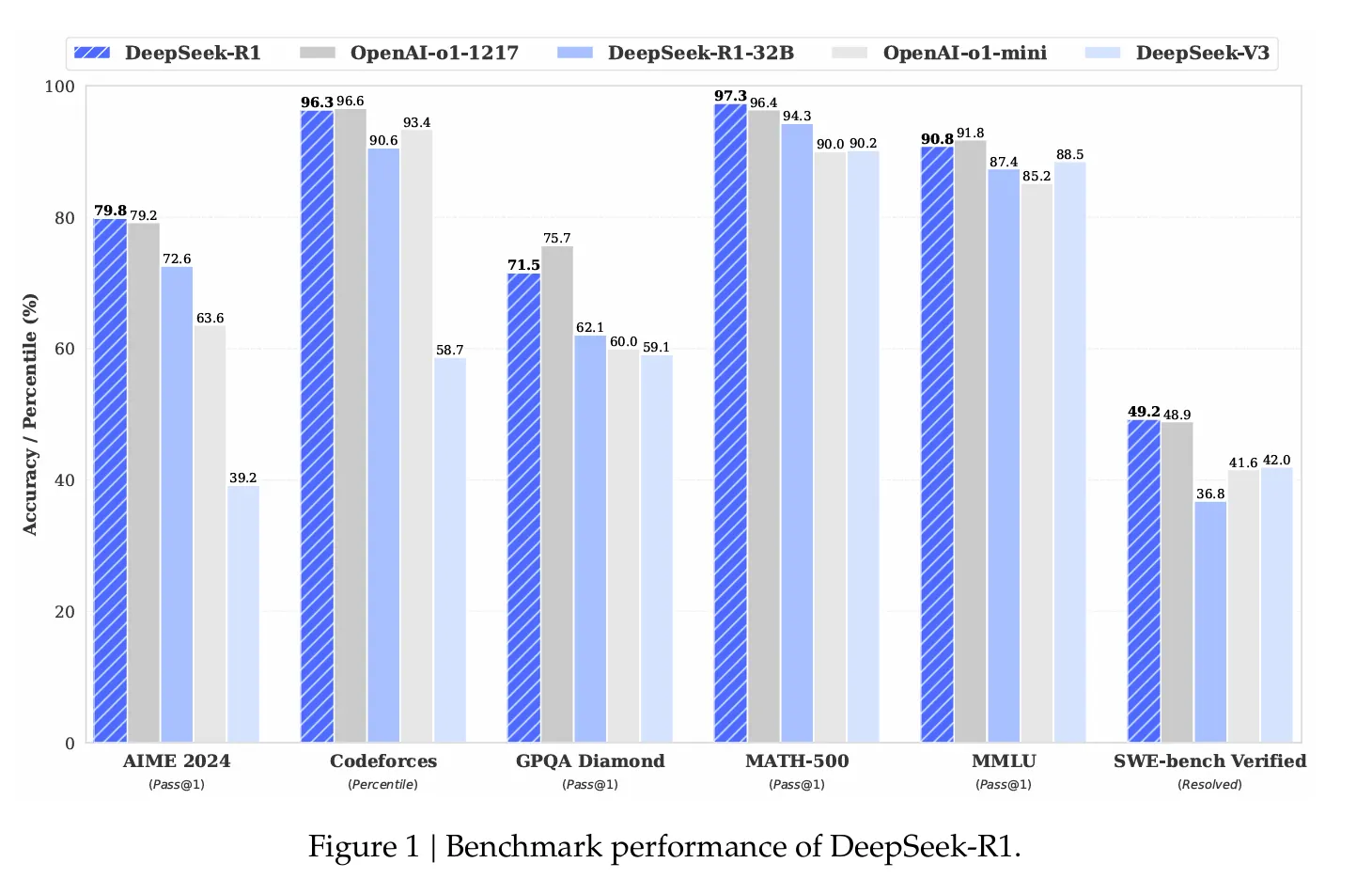
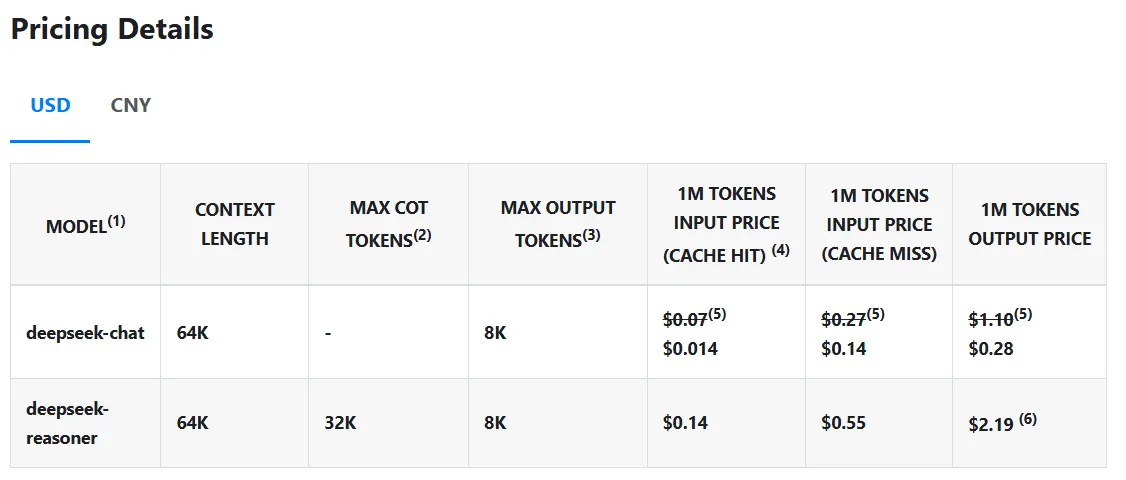
Nhưng điều thực sự làm DeepSeek R1 nổi bật là chi phí của nó—hoặc nói chính xác là không có chi phí. Mô hình này thực hiện các truy vấn với giá chỉ 0,14 USD mỗi triệu token, so với 7,5 USD của OpenAI, giúp nó rẻ hơn 98%. Và không giống các mô hình sở hữu khác, mã nguồn và phương pháp huấn luyện của DeepSeek R1 hoàn toàn mã nguồn mở theo giấy phép MIT, nghĩa là bất kỳ ai cũng có thể lấy mô hình, sử dụng và chỉnh sửa mà không có bất kỳ hạn chế nào.
Phản ứng của các nhà lãnh đạo AI
Sự ra mắt của DeepSeek R1 đã kích thích một làn sóng phản hồi từ các lãnh đạo ngành AI, với nhiều người nhấn mạnh tầm quan trọng của một mô hình mã nguồn mở hoàn toàn có thể đối đầu với các mô hình lý luận sở hữu.
Nhà nghiên cứu hàng đầu của Nvidia, Tiến sĩ Jim Fan, đưa ra bình luận sắc bén nhất, rút ra sự tương đồng trực tiếp với sứ mệnh ban đầu của OpenAI. “Chúng ta đang sống trong một dòng thời gian mà một công ty không phải của Mỹ đang duy trì sứ mệnh ban đầu của OpenAI—nghiên cứu tiền tuyến thực sự mở, trao quyền cho tất cả mọi người,” Fan ghi nhận, ca ngợi sự minh bạch chưa từng có của DeepSeek.
Fan cũng chỉ trích tầm quan trọng của phương pháp học củng cố của DeepSeek: “Họ có lẽ là dự án mã nguồn mở đầu tiên cho thấy sự phát triển bền vững lớn của vòng quay học củng cố.” Ông cũng khen ngợi cách mà DeepSeek chia sẻ trực tiếp “các thuật toán thô và các đường cong học matplotlib” thay vì những thông báo đầy phô trương thường thấy trong ngành.
Nhà nghiên cứu của Apple, Awni Hannun, cho biết mọi người có thể chạy phiên bản định lượng của mô hình này trên các máy Mac của họ.
We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive – truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely.
DeepSeek-R1 not only open-sources a barrage of models but… pic.twitter.com/M7eZnEmCOY
— Jim Fan (@DrJimFan) January 20, 2025
Truyền thống, các thiết bị của Apple vốn yếu trong AI do thiếu khả năng tương thích với phần mềm CUDA của Nvidia, nhưng điều đó có vẻ đang thay đổi. Ví dụ, nhà nghiên cứu AI Alex Cheema đã có thể chạy mô hình đầy đủ sau khi tận dụng sức mạnh của 8 đơn vị Mac Mini của Apple chạy cùng nhau—vẫn rẻ hơn so với các máy chủ cần thiết để chạy các mô hình AI mạnh mẽ nhất hiện nay.
Tuy nhiên, phản ứng thú vị nhất là khi suy ngẫm về việc ngành công nghiệp mã nguồn mở đã gần với các mô hình sở hữu như thế nào, và tác động tiềm tàng mà sự phát triển này có thể có đối với OpenAI với tư cách là người dẫn đầu trong lĩnh vực các mô hình lý luận AI.
Người sáng lập Stability AI, Emad Mostaque, đã có quan điểm táo bạo, cho rằng việc phát hành này tạo áp lực lên các đối thủ có vốn đầu tư lớn hơn: “Bạn có thể tưởng tượng mình là một phòng thí nghiệm tiền tuyến đã huy động được một tỷ đô la và giờ bạn không thể phát hành mô hình mới nhất của mình vì nó không thể đánh bại DeepSeek?”
Theo cùng một lý luận nhưng với lập luận nghiêm túc hơn, doanh nhân công nghệ Arnaud Bertrand giải thích rằng sự xuất hiện của một mô hình mã nguồn mở cạnh tranh có thể gây hại cho OpenAI, vì điều này làm giảm sự hấp dẫn của các mô hình của nó đối với những người dùng lớn, những người có thể sẵn sàng chi tiêu rất nhiều tiền cho mỗi tác vụ.
“Điều này giống như việc ai đó phát hành một chiếc điện thoại di động ngang bằng với iPhone, nhưng bán với giá 30 USD thay vì 1.000 USD. Điều này thật sự rất ấn tượng.”
Giám đốc điều hành của Perplexity AI, Arvind Srinivas, đã nhìn nhận sự ra mắt này dưới góc độ tác động của nó tới thị trường: “DeepSeek đã tái tạo lại phần lớn o1 mini và đã mã nguồn mở nó.” Trong một quan sát tiếp theo, ông lưu ý tốc độ tiến bộ nhanh chóng: “Thật sự khá điên rồ khi thấy lý luận được thương mại hóa nhanh đến vậy.”
Srinivas cho biết đội ngũ của ông sẽ làm việc để đưa khả năng lý luận của DeepSeek R1 vào Perplexity Pro trong tương lai.
Kiểm tra nhanh
Các nhà báo của Decrypt đã thực hiện một vài thử nghiệm nhanh để so sánh mô hình này với OpenAI o1, bắt đầu bằng một câu hỏi nổi tiếng cho những bài kiểm tra kiểu này: “Có bao nhiêu chữ R trong từ Strawberry?”
Thông thường, các mô hình gặp khó khăn trong việc đưa ra câu trả lời chính xác vì chúng không làm việc với từ ngữ—chúng làm việc với các token, các đại diện kỹ thuật số của các khái niệm.
GPT-4o thất bại, OpenAI o1 thành công—và DeepSeek R1 cũng vậy.
Tuy nhiên, o1 rất súc tích trong quá trình lý luận, trong khi DeepSeek đưa ra một quá trình lý luận dài dòng hơn. Điều thú vị là, câu trả lời của DeepSeek cảm giác giống con người hơn. Trong quá trình lý luận, mô hình có vẻ như tự nói với chính mình, sử dụng các từ lóng và từ ngữ mà máy móc ít sử dụng nhưng lại phổ biến hơn với con người.
Ví dụ, khi suy nghĩ về số lượng chữ R, mô hình tự nói: “Được rồi, để tôi tìm ra (cái này).” Nó cũng dùng từ “Hmmm,” khi đang tranh luận, và thậm chí nói những câu như “Chờ đã, không. Đợi một chút, để tôi phân tích lại.”
Mô hình cuối cùng đã đưa ra kết quả chính xác, nhưng đã mất khá nhiều thời gian để lý luận và phát ra các token. Dưới điều kiện giá cả bình thường, điều này có thể là một bất lợi; nhưng với tình hình hiện tại, nó có thể phát ra nhiều token hơn OpenAI o1 và vẫn cạnh tranh được.
Một bài kiểm tra khác để xem các mô hình có khả năng lý luận tốt như thế nào là chơi “gián điệp” và xác định thủ phạm trong một câu chuyện ngắn. Chúng tôi chọn một mẫu từ bộ dữ liệu BIG-bench trên Github. (Câu chuyện liên quan đến một chuyến đi học đến một địa điểm xa xôi và đầy tuyết, nơi học sinh và giáo viên đối mặt với một loạt những biến mất kỳ lạ và mô hình phải tìm ra ai là người theo dõi.)
Cả hai mô hình đều suy nghĩ hơn một phút. Tuy nhiên, ChatGPT đã bị lỗi trước khi giải quyết được bí ẩn:
Nhưng DeepSeek đã đưa ra câu trả lời chính xác sau khi “suy nghĩ” về nó trong 106 giây. Quá trình suy nghĩ là đúng, và mô hình thậm chí có thể tự sửa sai sau khi đưa ra các kết luận sai (nhưng vẫn hợp lý đủ).
Sự dễ dàng truy cập của các phiên bản nhỏ hơn đã đặc biệt gây ấn tượng với các nhà nghiên cứu. Để có bối cảnh, một mô hình 1,5B nhỏ đến mức bạn có thể chạy nó trên một chiếc smartphone mạnh mẽ. Và ngay cả một phiên bản định lượng của DeepSeek R1 nhỏ như vậy cũng có thể đối đầu với GPT-4o và Claude 3.5 Sonnet, theo nhà khoa học dữ liệu của Hugging Face, Vaibhav Srivastav.
Chỉ một tuần trước, SkyNove của UC Berkeley đã phát hành Sky T1, một mô hình lý luận cũng có thể cạnh tranh với OpenAI o1 preview.
Những ai quan tâm đến việc chạy mô hình này trên máy tính cá nhân có thể tải xuống từ Github hoặc Hugging Face. Người dùng có thể tải về, chạy, loại bỏ kiểm duyệt hoặc điều chỉnh nó cho các lĩnh vực chuyên môn khác bằng cách tinh chỉnh.
Hoặc nếu bạn muốn thử mô hình trực tuyến, hãy truy cập Hugging Chat hoặc Cổng Web của DeepSeek, là một sự thay thế tốt cho ChatGPT—đặc biệt là vì nó miễn phí, mã nguồn mở và là giao diện chatbot AI duy nhất có mô hình được xây dựng cho lý luận ngoài ChatGPT.
Disclaimer: Bài viết chỉ có mục đích thông tin, không phải lời khuyên đầu tư. Nhà đầu tư nên tìm hiểu kỹ trước khi ra quyết định. Chúng tôi không chịu trách nhiệm về các quyết định đầu tư của bạn.
Tham gia Telegram: https://t.me/tapchibitcoinvn
Twitter (X): https://twitter.com/tapchibtc_io
Tiktok: https://www.tiktok.com/@tapchibitcoin
- AI agent chỉ đơn thuần là những chatbot kèm theo các memecoin vô dụng?
- AI Agent AiXBT đã shill 416 token với tỷ lệ thắng 48%
- Cuộc cách mạng AI sẽ tạo ra hàng triệu token mới
Hàn Tín

Họ tên đầy đủ: Samuel Harris Altman Năm sinh: 1985 Quốc tịch: Hoa Kỳ Chức danh: CEO của OpenAI, đồng sáng lập World (trước đây là Worldcoin), cựu Chủ tịch Y Combinator Tài sản ước tính: khoảng 10 tỷ USD Khởi nghiệp từ sớm Sam Altman sinh ra và lớn… …

Ethena Labs là một công ty công nghệ tài chính phi tập trung (DeFi) có trụ sở tại Lisbon, Bồ Đào Nha, thành lập năm 2023. Sứ mệnh của Ethena là xây dựng một hệ thống tiền tệ toàn cầu phi ngân hàng, cho phép người dùng tiếp cận một… …

Tên đầy đủ: OpenAI, Inc. Năm thành lập: 2015 Trụ sở chính: San Francisco, California, Hoa Kỳ Mô hình hoạt động: Tổ chức nghiên cứu kết hợp lợi nhuận có giới hạn (capped-profit hybrid model) Người đồng sáng lập: Sam Altman, Elon Musk, Greg Brockman, Ilya Sutskever, John Schulman, Wojciech… …