Bitcoin
Bitcoin  Ethereum
Ethereum  XRP
XRP  Tether
Tether  BNB
BNB  Solana
Solana  USDC
USDC  Dogecoin
Dogecoin  Cardano
Cardano  Wrapped stETH
Wrapped stETH  Wrapped Bitcoin
Wrapped Bitcoin  Ethena USDe
Ethena USDe  Hyperliquid
Hyperliquid  Figure Heloc
Figure Heloc  Sui
Sui 








Các nhà nghiên cứu tại DeepMind của Google đã tiết lộ một phương pháp mới để tăng tốc độ huấn luyện AI, giúp giảm đáng kể tài nguyên tính toán và thời gian cần thiết. Phương pháp mới này đối với quy trình tiêu tốn năng lượng có thể làm cho việc phát triển AI nhanh hơn và rẻ hơn, theo một bài báo nghiên cứu gần đây – và điều này có thể là tin tốt cho môi trường.
“Phương pháp của chúng tôi – học tương phản đa phương thức với lựa chọn ví dụ chung (JEST) – vượt qua các mô hình hiện đại nhất với số lượng lần lặp ít hơn lên đến 13 lần và lượng tính toán ít hơn 10 lần,” nghiên cứu cho biết.
Ngành công nghiệp AI được biết đến với mức tiêu thụ năng lượng cao. Các hệ thống AI quy mô lớn như ChatGPT yêu cầu sức mạnh xử lý lớn, điều này đòi hỏi nhiều năng lượng và nước để làm mát các hệ thống này. Ví dụ, lượng nước tiêu thụ của Microsoft đã tăng 34% từ năm 2021 đến 2022 do nhu cầu tính toán AI tăng lên, với ChatGPT bị cáo buộc tiêu thụ gần nửa lít nước cho mỗi 5 đến 50 lần truy vấn.
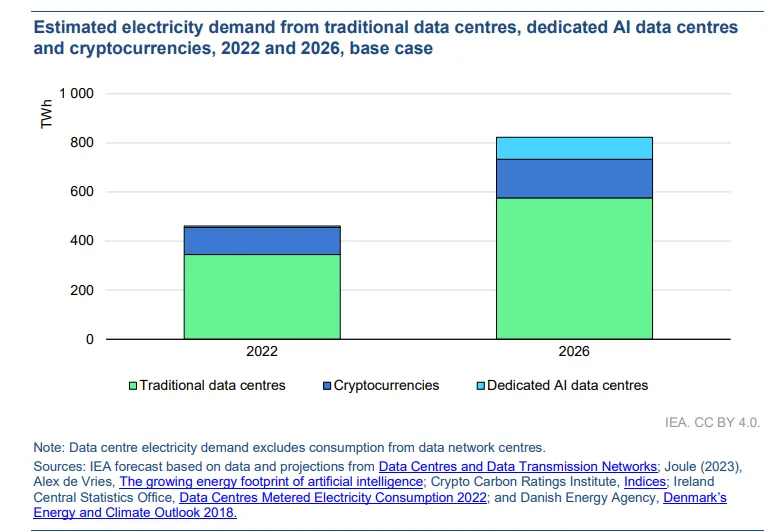
Cơ quan Năng lượng Quốc tế (IEA) dự đoán rằng tiêu thụ điện của trung tâm dữ liệu sẽ tăng gấp đôi từ năm 2022 đến 2026 – so sánh nhu cầu năng lượng của AI với hồ sơ năng lượng thường bị chỉ trích của ngành khai thác tiền điện tử.
Tuy nhiên, các phương pháp như JEST có thể cung cấp một giải pháp. Bằng cách tối ưu hóa việc chọn dữ liệu cho việc huấn luyện AI, Google cho biết, JEST có thể giảm đáng kể số lượng lần lặp và sức mạnh tính toán cần thiết, điều này có thể giảm tổng mức tiêu thụ năng lượng. Phương pháp này phù hợp với những nỗ lực cải thiện hiệu quả của các công nghệ AI và giảm tác động môi trường của chúng.
Nếu kỹ thuật này chứng minh hiệu quả ở quy mô lớn, những người huấn luyện AI sẽ chỉ cần một phần nhỏ sức mạnh để huấn luyện các mô hình của họ. Điều này có nghĩa là họ có thể tạo ra các công cụ AI mạnh mẽ hơn với cùng tài nguyên hiện có, hoặc tiêu tốn ít tài nguyên hơn để phát triển các mô hình mới.
Cách thức hoạt động của JEST
JEST hoạt động bằng cách chọn các lô dữ liệu bổ sung để tối đa hóa khả năng học của mô hình AI. Không giống như các phương pháp truyền thống chọn từng ví dụ riêng lẻ, thuật toán này xem xét thành phần của toàn bộ tập hợp.
Ví dụ, hãy tưởng tượng bạn đang học nhiều ngôn ngữ. Thay vì học tiếng Hoa, tiếng Hàn và tiếng Nhật riêng rẽ, có lẽ theo thứ tự độ khó, bạn có thể thấy hiệu quả hơn nếu học chúng cùng nhau theo cách mà kiến thức của một ngôn ngữ hỗ trợ việc học ngôn ngữ khác. Vì bạn biết rằng tiếng Hàn và tiếng Nhật có mối quan hệ chặt chẽ với tiếng Hoa, đặc biệt là Nhật Bản vẫn sử dụng rất nhiều Hán tự. Qua đó học cùng lúc 3 thứ tiếng sẽ bổ trợ cho nhau.
Google đã áp dụng cách tiếp cận tương tự và đã thành công.
“Chúng tôi chứng minh rằng việc chọn các lô dữ liệu chung hiệu quả hơn cho việc học so với chọn các ví dụ độc lập,” các nhà nghiên cứu tuyên bố trong bài báo.
Để làm như vậy, các nhà nghiên cứu của Google đã sử dụng “học tương phản đa phương thức,” nơi quá trình JEST xác định các phụ thuộc giữa các điểm dữ liệu. Phương pháp này cải thiện tốc độ và hiệu quả của việc huấn luyện AI trong khi yêu cầu ít sức mạnh tính toán hơn nhiều.
Yếu tố quan trọng của phương pháp này là bắt đầu với các mô hình tham chiếu đã được huấn luyện trước để hướng dẫn quá trình chọn dữ liệu, Google lưu ý. Kỹ thuật này cho phép mô hình tập trung vào các tập dữ liệu chất lượng cao, được quản lý tốt, tối ưu hóa thêm hiệu quả huấn luyện.
“Chất lượng của một lô dữ liệu cũng là một chức năng của thành phần của nó, ngoài chất lượng tổng hợp của các điểm dữ liệu được xem xét độc lập,” bài báo giải thích.
Các thí nghiệm của nghiên cứu đã cho thấy sự cải thiện hiệu suất rõ rệt trên nhiều tiêu chuẩn. Ví dụ, huấn luyện trên tập dữ liệu WebLI thông thường bằng JEST đã cho thấy sự cải thiện đáng kể về tốc độ học và hiệu quả sử dụng tài nguyên.
Các nhà nghiên cứu cũng nhận thấy rằng thuật toán này nhanh chóng phát hiện các lô con có khả năng học cao, tăng tốc quá trình huấn luyện bằng cách tập trung vào các mẩu dữ liệu cụ thể “phù hợp” với nhau. Kỹ thuật này, được gọi là “khởi động chất lượng dữ liệu,” coi trọng chất lượng hơn số lượng và đã chứng minh hiệu quả tốt hơn cho việc huấn luyện AI.
“Một mô hình tham chiếu được huấn luyện trên một tập dữ liệu nhỏ được quản lý tốt có thể hướng dẫn hiệu quả việc quản lý một tập dữ liệu lớn hơn nhiều, cho phép huấn luyện một mô hình vượt trội hơn hẳn về chất lượng so với mô hình tham chiếu trên nhiều nhiệm vụ khác,” bài báo cho biết.
Tham gia Telegram của Tạp Chí Bitcoin: https://t.me/tapchibitcoinvn
Theo dõi Twitter: https://twitter.com/tapchibtc_io
Theo dõi Tiktok: https://www.tiktok.com/@tapchibitcoin
- Hội đồng quản trị OpenAI bảo vệ CEO Sam Altman giữa những tuyên bố về ‘văn hóa độc hại’
- OpenAI sẽ kết hợp nội dung Reddit vào dữ liệu đào tạo AI của mình, cổ phiếu RDDT tăng 14%
- OpenAI thành lập một ủy ban an toàn mới giữa những tin đồn về GPT-5
- OpenAI là gì? Công ty AI đứng sau ChatGPT
Thạch Sanh
Theo Decrypt